

Introdução
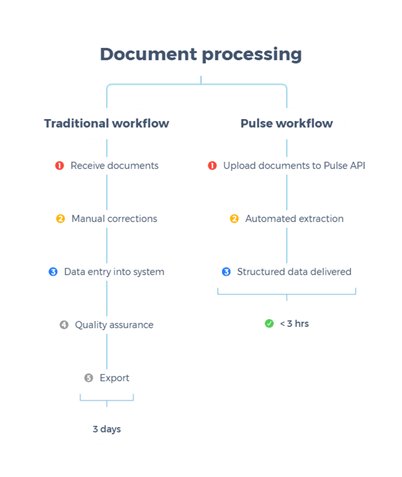
Organizações que lidam com grandes volumes de documentos financeiros — balanços, demonstrativos, contratos de empréstimo e faturas — enfrentam desafios únicos: layout variável, tabelas complexas, terminologia contábil e necessidade de precisão regulatória. Neste artigo mostramos um Technical How-to para construir um pipeline de extração e afinação de modelos que combina as capacidades de entendimento documental da Pulse AI com os serviços de Artificial Intelligence disponíveis via Amazon Bedrock. Vamos abordar arquitetura, armazenamento em Amazon Simple Storage Service (S3), fluxo de dados, métricas de qualidade e exemplos práticos de uso em produção.
Por que combinar Pulse AI e Amazon Bedrock?
A Pulse AI traz soluções de Partner solutions focadas em document understanding: OCR avançado, reconhecimento de tabelas, relacionamentos semânticos e extração de entidades específicas do domínio financeiro. O Amazon Bedrock, por sua vez, oferece acesso a modelos de fundação otimizados, infraestrutura gerenciada e controles de segurança compatíveis com ambientes corporativos. Juntos, eles permitem criar pipelines que entregam enterprise-grade accuracy na extração e interpretação de informações financeiras.
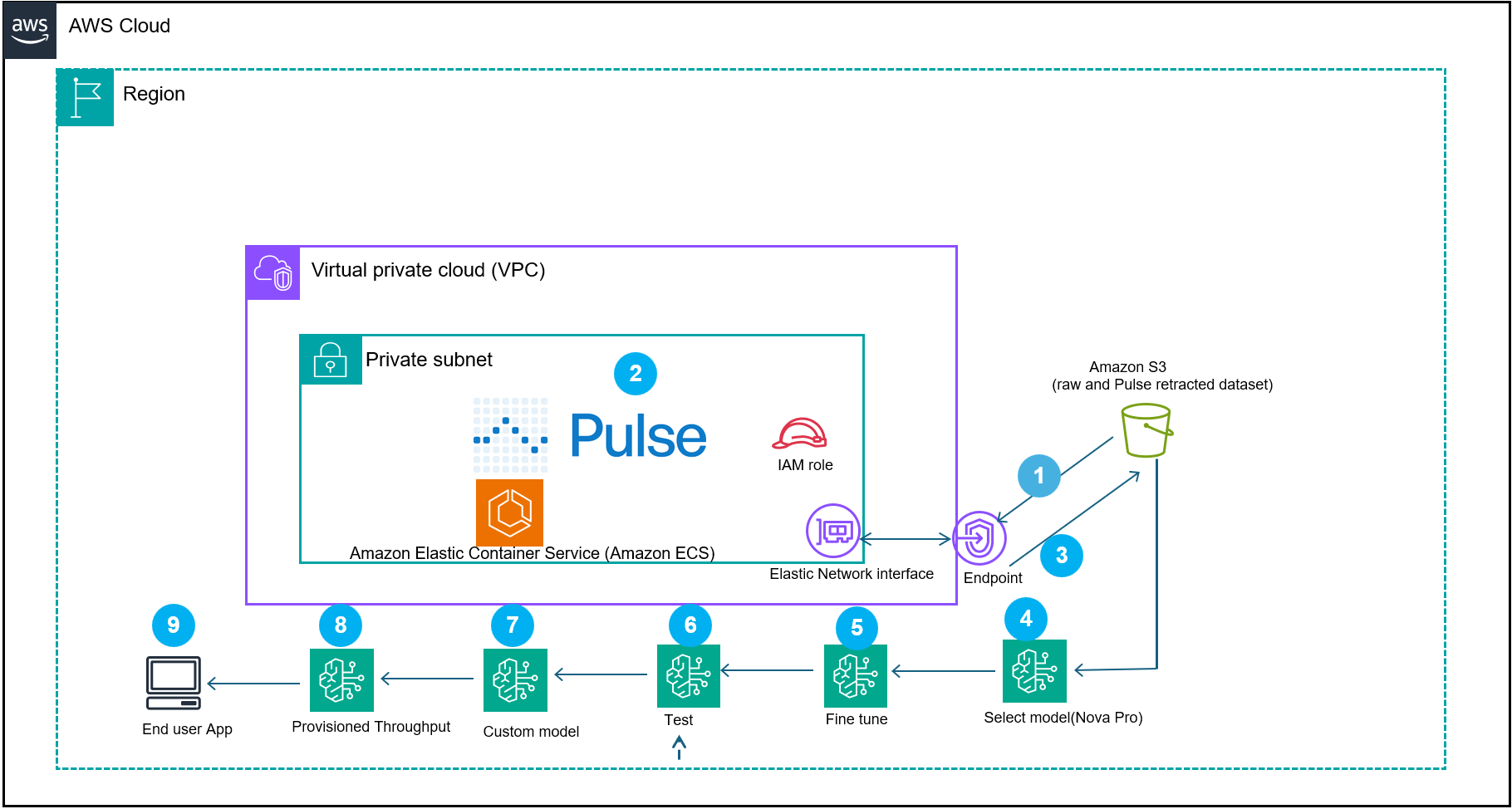
Visão geral da arquitetura
Um pipeline típico consiste em camadas bem definidas:
- Ingestão e Storage: documentos brutos enviados para Amazon Simple Storage Service (S3), com versionamento e políticas de ciclo de vida.
- Pré-processamento: normalização de PDFs/imagens, extração inicial de texto via OCR, limpeza e segmentação.
- Extração com Pulse AI: execução de modelos de entendimento documental para identificar campos, tabelas e relacionamentos.
- Modelos em Bedrock: uso de foundation models para normalização semântica, desambiguação de termos financeiros e geração de embeddings para pesquisa semântica.
- Armazenamento estruturado: resultados indexados em um datastore (por exemplo, Amazon RDS, DynamoDB ou um vetor DB), com os artefatos originais em S3.
- Monitoramento e retraining: pipeline de ML Ops para avaliar acurácia, rotular exemplos difíceis e afinar (fine-tune) modelos quando necessário.
Segurança e compliance
Use políticas de bucket S3, AWS KMS para criptografia em trânsito e em repouso, controle de acesso via IAM e logging com AWS CloudTrail. Para dados sensíveis, aplique mascaramento ou processos de anonimização antes de enviar para modelos externos, quando aplicável.
Passo a passo: implementando o pipeline
A seguir um roteiro prático para criar a solução:
1. Coleta e organização no Amazon S3
- Crie buckets separados para dados brutos, dados processados e artefatos de treinamento.
- Habilite versionamento e políticas de ciclo de vida para arquivar documentos antigos.
- Use nomes padronizados e metadados (ex.: tipo_documento/ano/cliente/id.pdf) para facilitar buscas e governança.
2. Pré-processamento de documentos
- Normalizar PDFs e imagens: unificar DPI, remover ruído e segmentar páginas.
- Executar OCR inicial (pode ser o OCR da própria Pulse AI ou Amazon Textract) para obter texto bruto.
- Detectar e extrair tabelas como objetos estruturados; salvar como CSV/JSON.
3. Extração avançada com Pulse AI
Envie os documentos pré-processados para os serviços da Pulse AI para identificação de entidades financeiras específicas (ex.: nomes de contas, valores, datas de vencimento, cláusulas contratuais). A Pulse AI é eficaz para capturar relações complexas entre campos, como linhas de provisões em um balanço ou condições de pagamento em contratos.
4. Enriquecimento e fine-tuning com Amazon Bedrock
- Utilize Bedrock para aplicar modelos de linguagem que realizem a normalização semântica e a desambiguação (por exemplo, interpretar “Receita Operacional” vs “Receita Bruta”).
- Gere embeddings para pesquisa semântica e correspondência entre documentos.
- Quando identificar padrões de erro ou casos de uso específicos, crie conjuntos rotulados e aplique fine-tuning (ou customização de modelo) via Bedrock para melhorar a acurácia no domínio financeiro.
5. Persistência e indexação
Armazene dados extraídos em um banco relacional ou NoSQL para consultas transacionais. Para pesquisa e recuperação por similaridade, indexe embeddings em um vetor DB (pode usar soluções gerenciadas ou open source rodando na AWS). Mantenha o original em S3 como fonte da verdade.
6. Monitoramento, avaliação e feedback loop
- Defina métricas: precisão por campo, recall de tabelas, taxa de erro por tipo de documento.
- Implemente painéis (ex.: Amazon CloudWatch, QuickSight) para acompanhar deriva de dados.
- Automatize pipeline de retraining: quando amostras identificadas como problemáticas forem rotuladas por especialistas, re-treine e reimplante modelos em Bedrock.

Exemplos práticos
Três cenários comuns onde a integração Pulse AI + Amazon Bedrock traz resultado mensurável:
1. Extração de faturas e conciliação
- Fluxo: ingestão das faturas em S3 → OCR → extração de campos (valor, vencimento, CNPJ) com Pulse AI → normalização de fornecedores via Bedrock → integração com ERP para conciliação automática.
- Benefício: redução do tempo de processamento manual e diminuição de erros de correspondência.
2. Análise de contratos de crédito
- Fluxo: armazenar contratos em S3 → extração de cláusulas financeiras e covenants com Pulse AI → sumarização e avaliação de risco com modelo em Bedrock → sinais para equipe de crédito.
- Benefício: visualização rápida de indicadores de risco e extração de obrigações contratuais críticas.
3. Processamento de demonstrações contábeis
- Fluxo: ingestão de relatórios em S3 → extração de tabelas e linhas contábeis com Pulse AI → mapeamento de contas e comparações temporais via Bedrock → dashboards financeiros.
- Benefício: rapidez na transformação de relatórios em dados analisáveis, suporte a auditoria e compliance.
Boas práticas e considerações finais
Para obter sucesso em produção, considere as seguintes recomendações:
- Planeje governança de dados desde o início: rotulagem, acesso, retenção e auditoria.
- Combine regras heurísticas com modelos estatísticos para capturar exceções.
- Use Partner solutions como Pulse AI para acelerar o entendimento do domínio e aproveitar recursos prontos à produção.
- Monitore continuamente a performance e mantenha um pipeline de fine-tuning para adaptar modelos a novas variantes de documentos.
- Priorize segurança e criptografia em todo o fluxo, especialmente ao usar Amazon Simple Storage Service (S3) como repositório central.
Conclusão
Ao combinar a capacidade de entendimento documental da Pulse AI com a infraestrutura e os modelos oferecidos por Amazon Bedrock, é possível construir pipelines robustos e escaláveis para processamento de documentos financeiros. O uso estratégico de Storage em Amazon S3, práticas de Technical How-to para pré-processamento e os mecanismos de personalização e monitoramento garantem que a solução entregue Artificial Intelligence com precisão empresarial. Para equipes de dados e TI, esse padrão arquitetural representa um caminho prático para transformar documentos complexos em insights acionáveis, reduzindo custos operacionais e melhorando a governança.



