

Introdução
Este artigo é um guia Advanced (300) e prático sobre como montar um fluxo de trabalho seguro e auditável para fine-tune de grandes modelos de linguagem (LLMs) integrando Databricks Unity Catalog e Amazon SageMaker AI, com pré-processamento em Amazon EMR Serverless. O objetivo é demonstrar como acessar dados governados sem comprometer segurança ou conformidade, manter rastreabilidade (lineage) entre serviços, ajustar o modelo Ministral-3-3B-Instruct e registrar os artefatos treinados de volta no Unity Catalog.
Visão geral da solução
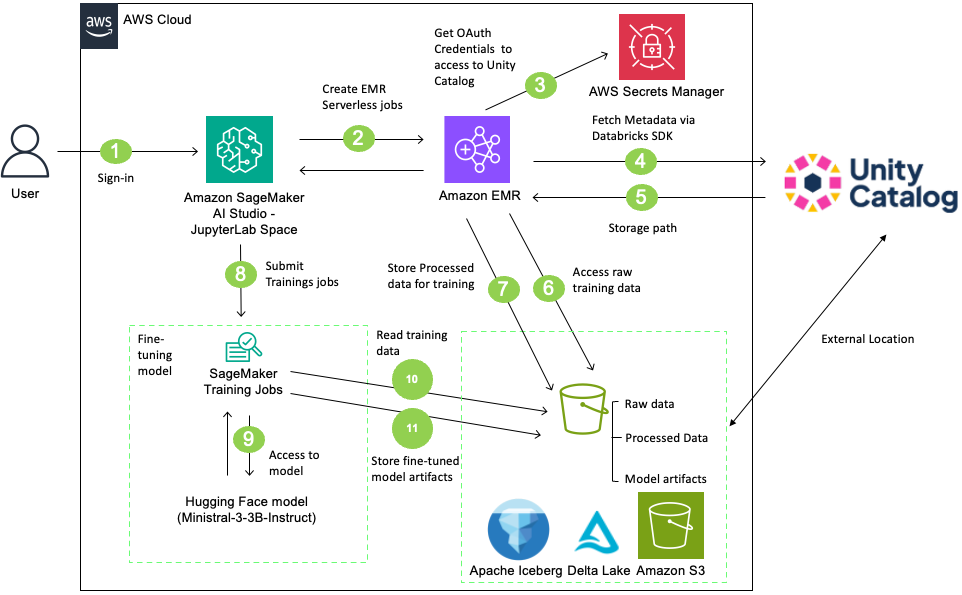
Arquiteturalmente, a solução combina três blocos principais:
- Databricks Unity Catalog: gestão centralizada de metadados, políticas de acesso e governança dos dados brutos e das saídas.
- Amazon EMR Serverless: execução de cargas de trabalho Spark para limpeza, balanceamento e transformação de dados em escala para treino.
- Amazon SageMaker AI: ambiente de fine-tuning e inferência para ajustar o modelo Ministral-3-3B-Instruct e armazenar artefatos treinados.
Entre esses blocos, mantenha controle de acesso por IAM, políticas de acesso ao S3 (external locations do Unity Catalog) e registro de metadados/lineage para auditabilidade.
Por que essa abordagem?
- Permite continuar usando serviços já adotados pela organização (Databricks e AWS) sem sacrificar governança centralizada.
- Garante que os dados sensíveis nunca sejam expostos desnecessariamente: os dados brutos ficam em local governado e o processamento é feito com credenciais e VPC controladas.
- Habilita rastreabilidade entre transformação, treinamento e modelos finais, essencial para compliance em projetos de Artificial Intelligence.
Pré-requisitos e princípios de segurança
Antes de começar, verifique:
- Unity Catalog configurado com external locations apontando para buckets S3 governados.
- Roles IAM com políticas mínimas (least privilege) para EMR Serverless e SageMaker, incluindo acesso controlado aos buckets S3 e KMS para criptografia de dados em repouso.
- Conexões VPC, endpoints de S3 e configurações de segurança (security groups) para isolar tráfego entre serviços.
- Mecanismos de auditoria ativados (CloudTrail, Databricks audit logs) para registrar operações sobre dados e modelos.
Fluxo passo a passo (Technical How-to)
1) Preparar dados governados no Unity Catalog
Organize seus dados como tabelas Delta ou arquivos parquet dentro do external location do Unity Catalog apontando para S3. Mantenha os catálogos e permissões atualizados para usuários e roles que irão acionar o EMR ou SageMaker.
2) Pré-processamento com Amazon EMR Serverless
Use EMR Serverless para executar jobs Spark que leem os dados governados (via S3) e produzem um dataset final preparado para fine-tune (por ex., JSONL com prompts e completions). Exemplo de passos:
- Configurar job EMR Serverless com role IAM que tenha acesso restrito ao S3 e KMS.
- Rodar transformação: limpeza de texto, normalização, truncamento de tokens, deduplicação e split de treino/validação.
- Salvar saída em um prefix governado do S3 e registrar a transformação em um Delta table (ou em metadados do Unity Catalog) para lineage.
Comandos típicos (resumo):
- Submeter job Spark ao EMR Serverless via AWS CLI ou API.
- Confirmar que artefato preprocessado foi escrito em s3://bucket-governado/prefix/ e que o Unity Catalog tem metadado associado.
3) Fine-tune no Amazon SageMaker AI
Utilize Amazon SageMaker AI para o treinamento do modelo Ministral-3-3B-Instruct. Pontos cruciais:
- Crie um role SageMaker com permissão estrita ao prefix S3 onde os dados preprocessados residem.
- Escolha instâncias compatíveis com o custo/performance desejado (GPU/MLP infra) e configure checkpoints em S3 governado.
- Forneça hyperparameters adequados (lr, batch_size, epochs) e use toolchain compatível para o modelo Ministral-3-3B-Instruct.
Durante o treinamento, registre metadados do experimento: dataset origin (referência para a tabela/entry do Unity Catalog), commit do preprocessing, métricas e checkpoints — isso vai compor o lineage entre dados e modelo.
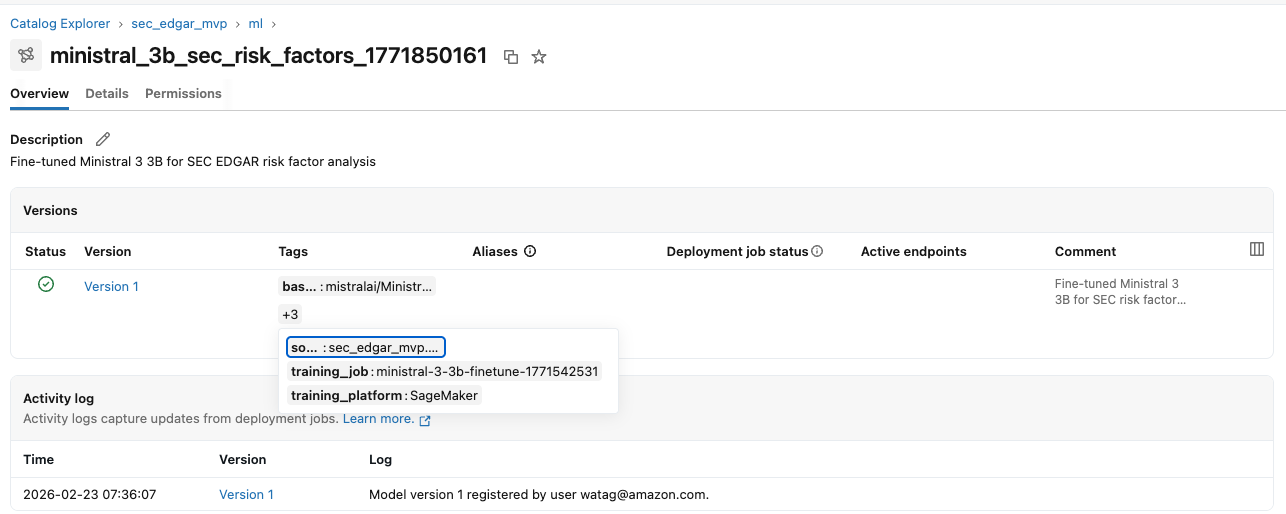
4) Registrar artefatos de volta no Unity Catalog
Após o fine-tune, armazene os artefatos (pesos, tokenizer, configuração) em um prefix S3 governado. Em seguida, atualize o Unity Catalog com entradas que apontem para esses artefatos e incluam metadados de treinamento (dataset source, id do job EMR, id do job SageMaker, métricas, training config).
Se você usa Databricks Model Registry, pode integrar via API para criar um registro do modelo com link para o local S3 e anotações de lineage. Assim, equipes que consomem modelos dentro do ecossistema Databricks mantêm governança e visibilidade.
Exemplos práticos

Exemplo resumido de sequence de chamadas:
- Submeter job EMR Serverless: aws emr-serverless start-job-run –application-id … –execution-role-arn
–job-driver … - Verificar saída em S3 e criar/atualizar entrada no Unity Catalog (via Databricks APIs ou UI): adicionar referencia para s3://bucket-governado/preprocess/job-123/
- Iniciar job SageMaker: aws sagemaker create-training-job –training-job-name … –role-arn … –input-data-config … –output-data-config …
- Ao final do job, copiar model.tar.gz para s3://bucket-governado/models/ministral-3-3b-instruct/fine-tuned/job-123/ e registrar no Unity Catalog / Model Registry.
Esses passos devem ser formalizados em pipelines (CI/CD) com validações automáticas, testes de qualidade e gates de governança para deployment em produção.
Lineage e conformidade
Mantenha uma estratégia única de metadados: atribua IDs únicos para cada artefato (dataset-preprocess-id, training-job-id, model-id). Capture logs e eventos no CloudTrail e Databricks audit logs e correlacione-os por IDs. Dessa forma você terá um rastro completo desde a fonte do dado até o modelo implantado — essencial para auditorias e requisitos de Artificial Intelligence responsáveis.
Boas práticas operacionais
- Use KMS para criptografia a nível de bucket e configure políticas de rotação de chaves.
- Implemente monitoring e alarme para jobs EMR e SageMaker (CloudWatch, Databricks alerts).
- Valide o conteúdo dos datasets após pré-processamento com checksums e amostragens automatizadas.
- Automatize o registro de metadados e a geração de relatórios de lineage para reduzir risco humano.
Conclusão
Integrar Databricks Unity Catalog, Amazon EMR Serverless e Amazon SageMaker AI fornece um caminho robusto para realizar fine-tuning de LLMs como o Ministral-3-3B-Instruct, preservando governança, segurança e rastreabilidade. Esta abordagem permite que organizações continuem usando suas ferramentas existentes, mantendo um ponto único de controle sobre dados e modelos. O resultado é um pipeline Advanced (300) e de produção que atende a requisitos de compliance sem sacrificar eficiência ou escalabilidade — uma receita prática para projetos de Artificial Intelligence em ambientes empresariais.


