On the night of March 7, Andrej Karpathy pushed a 630-line Python script to GitHub and went to sleep. By morning, his agent had run 50 experiments, discovered a better learning rate, and committed the proof to git without a single human instruction in between.
The story making the rounds is about autonomous machine learning (ML) research. But the more important story is about the design pattern underneath it, and the 40-line Markdown file that made the whole thing work.
The patterns in AutoResearch mirror methodology that any laboratory scientist would recognize. A fixed experimental protocol. A single variable under test. An objective measurement criterion. A keep-or-discard decision at the end of each run. A lab notebook that bridges the scientist’s intent and the instrument’s execution. This article extracts the three primitives that make the loop generalizable and shows why the shift from code to structured prose as the human-agent interface is a development worth paying attention to.
What is the Karpathy Loop?
The original problem AutoResearch was built to solve is narrow and specific. Karpathy was pretraining small transformer language models and spending significant research time in a manual loop: Modify a hyperparameter or architectural choice in the training script, run the model for a while, read the validation metric, decide whether the change was worth keeping, and repeat.
The repo automates that loop entirely. The training script is a stripped-down derivative of nanochat, Karpathy’s own minimal LLM training framework, condensed to a single GPU and a single file. The metric it optimises is val_bpb, validation bits per byte, chosen because it is vocabulary-size-independent, allowing the agent to change tokenisation or model architecture between runs and still get a fair comparison.
A typical session runs roughly 12 experiments per hour. An overnight run on a single GPU can cover 80 to 100 experiments, exploring a region of the configuration space that would take a human researcher several working days to traverse manually. That is the concrete problem. The insight worth extracting is that the solution Karpathy reached is not specific to language model pretraining at all.
AutoResearch is built on three primitives, not one.
- Editable asset. The single file the agent is permitted to modify. Confining the agent here keeps the search space interpretable and every hypothesis reviewable as a diff.
- Scalar metric. The single number that determines whether a change was an improvement. It must be computable without human judgment and unambiguous about direction.
- Time-boxed cycle. The fixed duration makes every experiment directly comparable, regardless of what the agent changed.
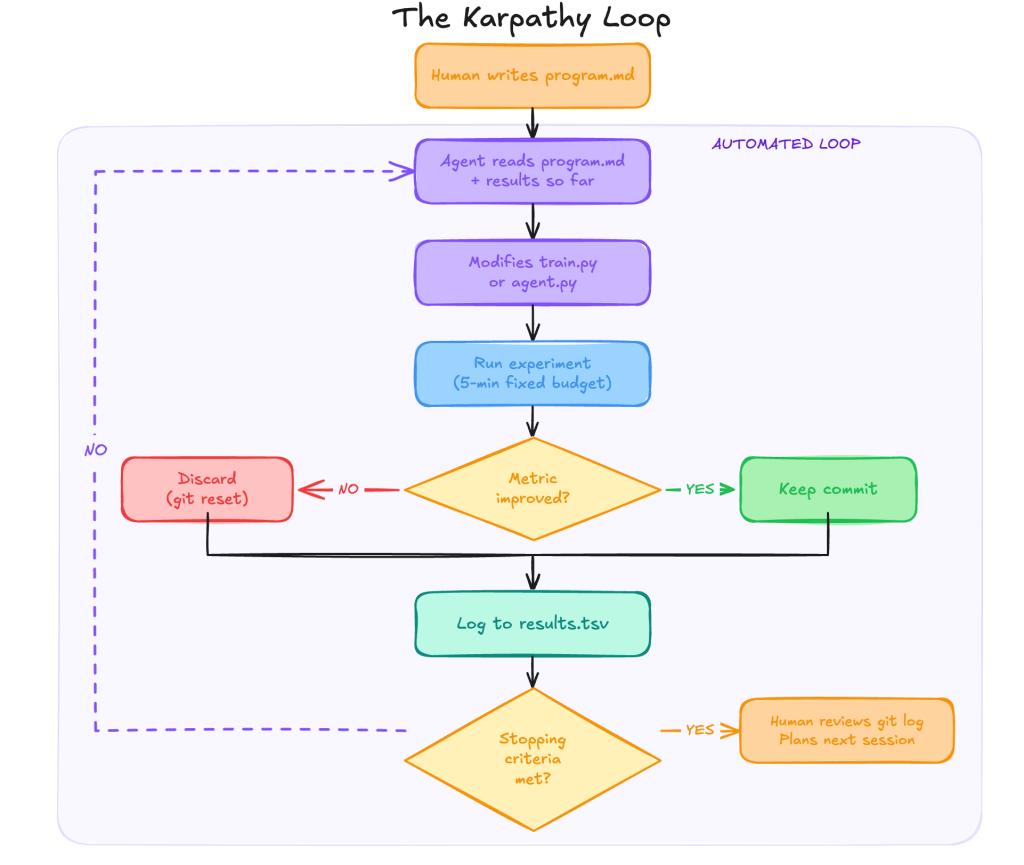
These three things together, not the agent, not the GPU, not the model architecture, are what make the loop generalizable beyond ML training.
Each constraint is doing specific engineering work. The fixed-time budget makes every experiment directly comparable, regardless of hardware, because both doubling model size and halving the learning rate consume the same compute and are judged on equal terms. The single editable file keeps the search space interpretable and every hypothesis reviewable as a diff; the git log becomes a legible experiment journal. The single scalar metric eliminates ambiguity about what “better” means, and it must be computable without human judgment.
Any metric that requires a committee to interpret, or that optimises a proxy rather than the actual outcome, will be exploited by an autonomous loop with relentless efficiency. Goodhart’s Law applies with particular force when the agent running 100 experiments per night has no off switch. AutoResearch is not minimal because Karpathy ran out of time. It is minimal by design.
Markdown is the human-agent interface
The most underappreciated file in the AutoResearch repository is not train.py. It is program.md. This single Markdown document simultaneously carries three registers of communication: instructions (what the agent should search for), constraints (what must not change), and stopping criteria (when the loop should wrap up and report). No other common format handles all three. YAML encodes structure but not reasoning. Python is executable but not legible as a strategy. JSON has no narrative. Markdown sits at the exact intersection of human editability and agent parseability.
The broader pattern is already visible across the tooling ecosystem. CLUADE.md files in Claude Code repositories govern agent behaviour for each codebase without touching the source code. Cursor rules files encode project conventions that persist across sessions.
GitHub Copilot custom instructions direct generation style at the repository level. System prompt documents are now version-controlled alongside application code in production agentic systems. Teams across the industry are independently converging on the same discovery: Structured natural language documents are the most durable way to encode human intent for autonomous agents, and Markdown is winning by default because it has just enough structure, specifically headings, emphasis, and code fences, to give agents reliable parsing anchors without requiring specialised tooling to maintain.
The implication for practitioners is direct. Writing a good program.md is the highest-leverage skill in an autonomous experiment loop. Not writing the training script. Not configuring the agent. The document must be precise enough to constrain the search, flexible enough to permit discovery, and explicit enough about failure conditions to prevent the loop from optimising toward a metric that no longer reflects the actual goal. This is not a soft skill. It is engineering work that happens to produce prose rather than code.
A traditional lab notebook records what was done and why. program.md inverts this; it records what should be done and why, before a single experiment runs. Configuration formats enforce schemas and require parsers. Markdown tolerates the natural imprecision of intent expression while still giving agents reliable parsing anchors. An agent reading a constraint such as “do not modify the classifier head architecture” understands it in context, not as a formal rule. The quality of an autonomous session is bound by the quality of that document. Teams that treat program.md as a throwaway prompt will get throwaway results. The git history of program.md is as valuable as the git history of train.py.
The Pattern That Goes Beyond ML Experiments
The ML training loop is the first instantiation of the Karpathy Loop, not its definition. Any system that exposes a scriptable asset, produces a measurable scalar outcome, and tolerates a time-boxed evaluation cycle is a candidate for the same pattern. Three non-ML applications demonstrate the transfer cleanly.
Database query optimisation maps the pattern directly: the editable asset is a query configuration file, the scalar metric is p95 latency measured by an automated benchmark suite, and the fixed time budget is however long the benchmark takes to run against a fixed dataset. The agent modifies the query structure, index hints, and caching strategy; the benchmark scores each variant; and the best configuration is accumulated in git. What currently occupies senior database engineers for days becomes an overnight autonomous run.
Customer support ticket routing follows the same structure: the editable asset is a routing rules configuration or a classification prompt; the scalar metric is accuracy against a labelled hold-out set of resolved tickets; and the feedback cycle is the time it takes to run the classifier against that set. An agent that modifies routing logic, category definitions, and fallback handling can run hundreds of experiments overnight and surface a configuration that meaningfully reduces misrouting rates, directly translating into reduced support costs.
The most direct validation of the pattern’s generalisability comes from Harrison Chase, founder of LangChain. Within days of Karpathy’s release, Chase published autoresearch-agents, adapting the loop entirely for agent optimisation. The editable asset is agent.py, which contains the agent’s prompts, tools, and architecture. The fixed components are run_eval.py and dataset.json, the evaluation harness and test cases that the loop must never touch. The scalar metric is the LangSmith evaluation score, computed automatically after each experiment run. Chase built it as a production-ready template with explicit support for any agent framework, including LangChain, LangGraph, the Anthropic SDK, and plain Python, which means any team running an agent in production can drop their own agent.py into the harness and let the loop run overnight.
The common thread across every row is a program.md equivalent, a human-written document that defines the search strategy, encodes the constraints, and specifies what the agent must not change. The quality of that document is the binding constraint on the quality of the loop.
The human role shifts to experimental design
Running AutoResearch on a dual-RTX-4090 system for a MobileNet V3 image classification task makes the division of labour concrete. The baseline reached 95.6% validation accuracy in the first five-minute run. The agent then ran a learning-rate sweep across four candidates, identified the optimal value, and proceeded to scheduler and augmentation experiments, all without intervention. The human’s contribution was just writing the program.md: deciding what to fix (the dataset pipeline and evaluation logic), what to free (learning rate, scheduler type, augmentation policy), what to measure (validation accuracy), and what the agent should not touch (the pretrained backbone weights).
That 30-minute investment in experimental design yielded overnight results from validated hyperparameter findings, ready to apply to a full-scale training job on larger hardware. The agent did not replace the researcher. It eliminated the repetitive execution work, specifically the running, waiting, recording, and deciding of each individual experiment, so that the researcher’s time went entirely toward the decisions that require domain knowledge and judgement.
The shift from writing code to writing experimental protocols is not a downgrade. A researcher who cannot articulate what must stay fixed, what should vary, and what constitutes improvement does not yet understand the problem well enough to experiment on it usefully.
The output of a session is not a trained model but a git log of validated decisions, each commit representing a change that demonstrably improved the metric. Reading that log, covering which changes helped and which directions were exhausted, is a new analytical skill that compounds with practice. The practical structure is two sessions with a human review in between: the first explores broadly across the learning rate, optimiser, and scheduler space; the second narrows to the two or three combinations that consistently scored highest. The researcher’s judgment enters the loop exactly where it adds value.
What’s next
For platform engineers and ML practitioners, the patterns in AutoResearch are immediately applicable: The editable asset behaves like a controlled variable in any well-designed experiment, the scalar metric functions like a fitness criterion in any optimisation problem, and the program.md document works like an experimental protocol, as any serious research organization would version-control and review it with the same rigour applied to production code.
What Karpathy demonstrated is that the gap between “running experiments manually” and “having an agent run experiments autonomously” is smaller than most teams assume, and the primary investment required is in document authorship rather than infrastructure.
The next frontier for this pattern is evaluation methodology, applying the loop to domains where the metric itself is the research question rather than a given. Indic language model evaluation is one such domain, where the search space of prompt templates, scoring functions, and benchmark construction choices is vast, and the systematic exploration of that space is precisely the independent evaluation infrastructure that sovereign AI deployments require.
As autonomous experiment loops mature from ML training into evaluation research, the discipline of writing clear, constraining, version-controlled instruction documents will define which teams produce reliable results and which produce confidently optimised noise. Stay tuned.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTube
channel to stream all our podcasts, interviews, demos, and more.

